

Olá, pessoal
No último dia 05/12 a Veeam lançou a nova versão 12.1 do Veeam Data Platform. Essa versão adicionou algumas novas funcionalidades e melhorias que podem ser vistas no documento What’s New.
Uma dessas novas funcionalidades é a habilidade de fazer backups de dados que estão armazenados em Object Storage, seja ele um storage que utiliza esse formato ou na Cloud. É muito comum hoje em dias existir dados que são armazenados nas principais Clouds em Object Storage que precisam ser protegidos e com essa nova funcionalidade isso agora é possível.
Nesse artigo vou demonstrar como adicionar o Object Storage ao VBR e a criar o job.
Pré-Requisitos
É suportado o seguinte tipo de Object Storage como origem dos dados:
- Amazon S3
- Azure Blob storage
- S3 Compatible Object Storage: qualquer origem que seja compatível com a API do S3, como outras clouds (IBM, Wasabi, Zadara, Oracle) e storages compatíveis (MinIO)
Existem também as seguintes limitações:
- Não é suportado backup e restore de dados para o Azure Data Box Storage e Azure Stack Edge
- Não é suportado o backup e restore do AWS Snowball Edge Storage
Adicionando Object Storage
Na versão 12.1 agora temos uma seção de “Dados Não Estruturados” na seção de Inventory. É nessa parte que iremos adicionar o Object Storage a ser protegido.
É nessa seção também onde podemos adicionar um File Share para ser protegido. Antes o nome era “NAS Backup”, mas agora com a adição do Object Storage foi renomeado para “Unstructured Data”.
Clique em “Add Data Souce” para iniciar o processo.
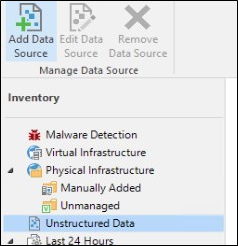
Clique em “Object storage”.

Nesse exemplo vou proteger um Storage Account na Azure que possui diversos arquivos de imagem, então vou escolher a opção Azure Blob Storage.

Escolha um nome para Storage Account, esse nome é apenas para identificação.
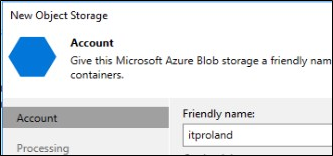
Em credenciais, adicione as credenciais do Blob. É possível escolher a opção de “Shared Key” ou “Entra ID”.
Usando a opção Shared Key você precisa do nome do Storage Account e da Shared Key que pode ser coletada nas opções do Storage Account.
Já a opção Entra ID você irá autenticar e adicionar a conta de acesso a Azure.
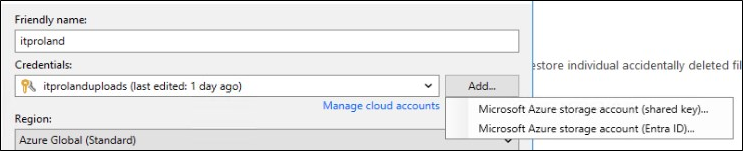
No meu exemplo utilizei a Shared Key para simplificar o processo.
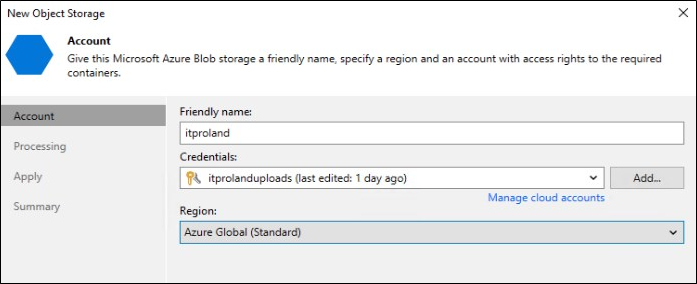
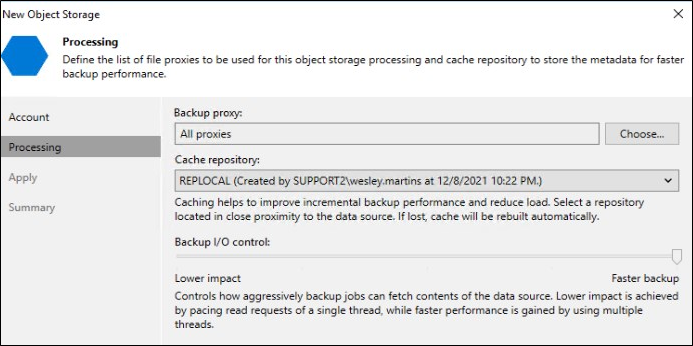
Em “Backup Proxy” você deve escolher um proxy para fazer a conexão com o Object Storage. Em meu caso eu tenho apenas o VBR como proxy então deixarei marcada a opção “All proxies”.
Em “Cache repository” você deve escolher um repositório para ser utilizado como Cache para melhorar a performance do backup incremental. Como nesse caso estamos fazendo backup de um Object Repository localizado na Cloud, a localização do repositório não será importante.
Em Backup I/O control você pode controlar o quão agressivo será feito a leitura dos dados no Object Storage. Nesse caso, como a origem é um Object Storage da Azure eu deixei a opção mais agressiva possível.
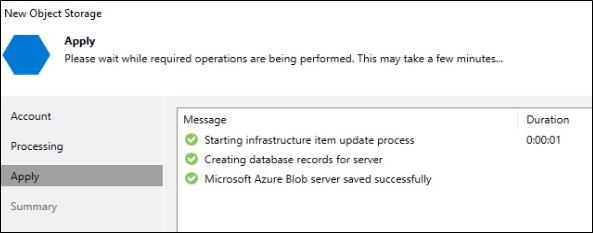
As opções serão validadas e o Object Storage será criado.
Em Object Storage veremos o novo Blob adicionado.

Criando Job de Backup
Agora que temos o objet adicionado a infraestrutura do Veeam podemos criar o job.
Clicando no Object Storage escolha a opção “Add to backup job”.
Escolha um nome e descrição para o job.
O Object Storage que adicionamos já virá incluído, mas é possível adicionar outros se necessário.
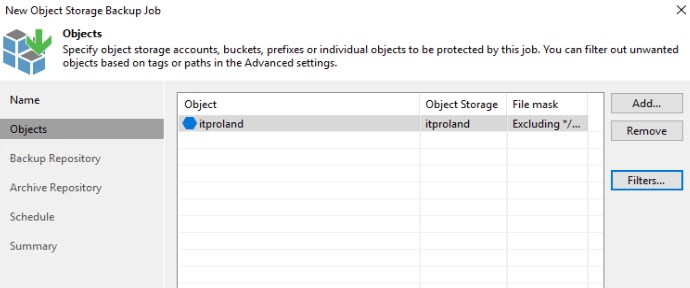
Em Filters é possível adicionar exclusões. Por padrão já é adicionado o Container “Veeam” para evitar que você faça backup de arquivos do Veeam caso você use esse Storage Account para armazenar backups também.
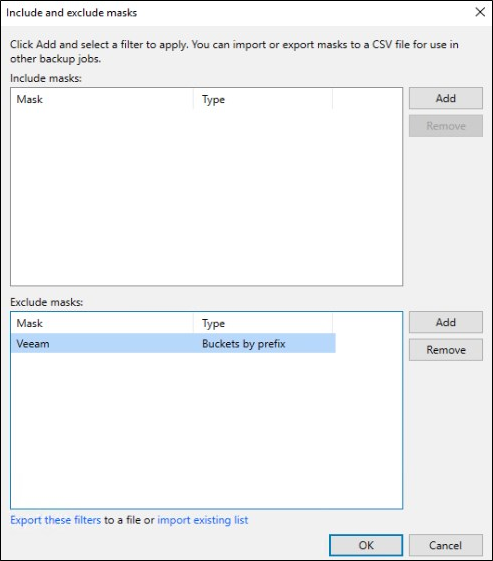
Escolha o repositório e quantas versões dos arquivos você quer manter. Essa opção funciona como a retenção de um job de backup, você conseguirá restaurar versões antigas de arquivos caso eles sejam modificados.
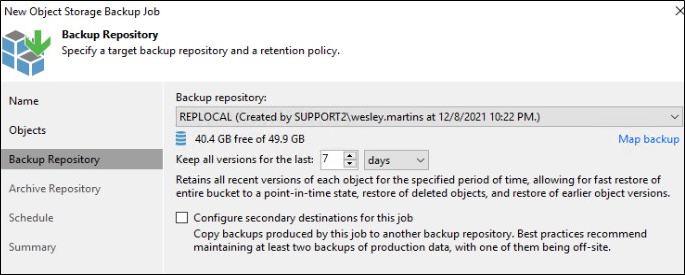
Em Archive Repository temos algumas opções.
- Archive recente object versions – Os objetos serão copiados para o outro repositório para manter a versão mais recente caso o repositório primário seja perdido.
- Archive previous object versions – Nessa opção você pode escolher uma retenção para as versões dos objetos mais antiga que a configurada no job. Ou seja, no meu exemplo, versões mais antigas que 7 dias serão armazenadas por 3 anos em outro repositório.
- Files to archive – É possível definir um filtro específico para os tipos de arquivos que gostaria de arquivar. Esse filtro não impacta o filtro original do job.
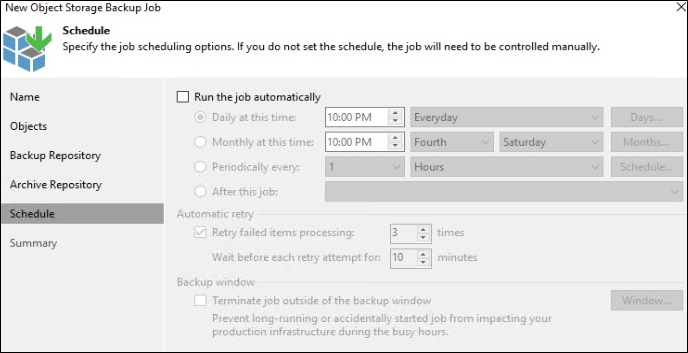
Escolha o agendamento do job e finalize a criação.
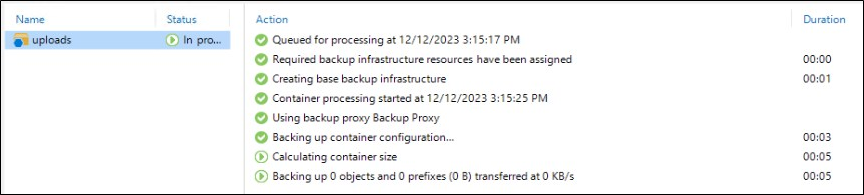
Ao executar o job o VBR irá verificar o tamanho do Container e iniciar o backup dos arquivos.
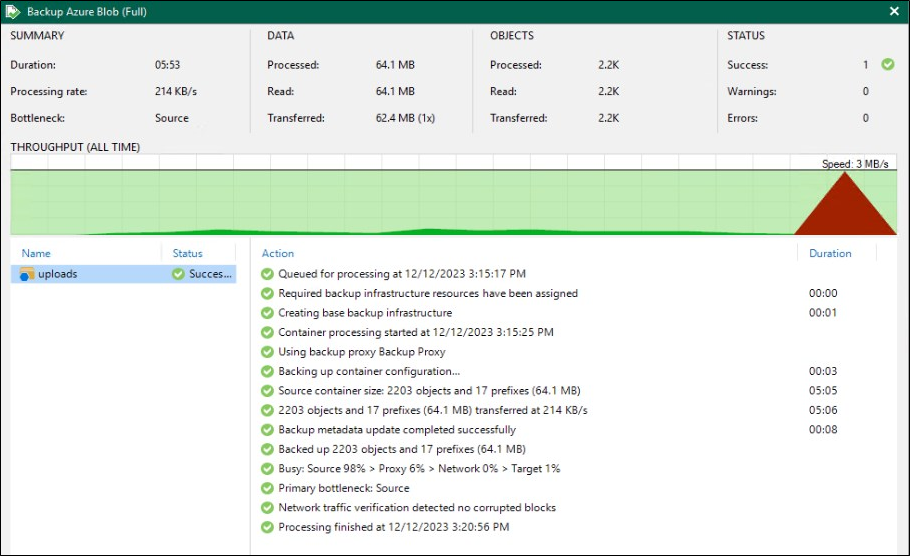
No meu exemplo foram feitos backups de 2203 objetos.
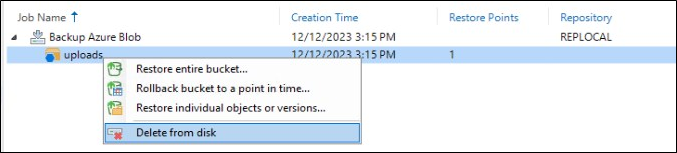
Após a finalização do backup ele estará disponível para restore.
Vídeo sobre o processo passo a passo.
Para maiores detalhes sobre o backup de Object Storage verifique os links abaixo:
- Unstructured Backup Data
- How Unstructured Data Backup to Object Storage Repository Works
- Creating Backup Jobs for Protecting Unstructured Data
- Object Storage Data Recovery